從ChatGPT到Optimus都中槍?楊立昆為什麼說現在的AI路線根本錯了?世界模型JEPA才是未來?
最近(大概就在達沃斯論壇那陣子,2026年1月左右),Yann LeCun(楊立昆,圖靈獎得主、卷積神經網路之父、前Meta AI首席科學家,現在自己開AMI Labs)在AI House的閉門會上,直接開砲說:
「目前所有做人形機器人的公司,一家都沒有真正知道怎麼讓這些機器人變得夠聰明、能在真實世界派上用場!」
這話一出,直接戳到Elon Musk(馬斯克)的痛點,因為他把特斯拉的未來很大一部分押在Optimus(擎天柱)人形機器人上。現場影片被截出來傳到X上,有人酸楊立昆「怎麼老是這麼負面、潑冷水」,馬斯克馬上跳出來酸回去:
「Yann覺得自己做不到,就覺得別人也做不到。」
(超酸的嘲諷滿點!)
楊立昆當然不吞這口氣,幾小時後就回擊:
「恰恰相反,我知道我做得到,我也知道怎麼做。只是現在大家賭的那些技術路線(大語言模型那一套)根本走不通。我賭的是JEPA(聯合嵌入預測架構)、世界模型(world models)、跟規劃(planning)。總有一天你們會發現我才是對的。」
這場對嗆不只是兩個大佬的嘴砲,而是AI發展路線的大分水嶺。下面用台灣國語口語風格,加上圖解,來好好拆解楊立昆到底在吵什麼、為什麼他敢這樣硬嗆馬斯克。
第一層:語言其實很「簡單」,生成式AI騙不了真正智能
現在大家看到ChatGPT、Gemini、Claude寫文章、寫程式、翻譯超猛,就覺得「哇,這就是智能啦!」
楊立昆直接潑冷水:語言是人類把真實世界高度壓縮、抽象化後的符號。文字裡面沒有顏色、重量、溫度、物理碰撞的細節。大語言模型只是在學這些符號之間的機率關係,它在玩「統計模仿」,不是真的理解世界。
生成圖片/影片的擴散模型(像Midjourney、Sora)也一樣,試圖像素級預測未來,但真實世界太多隨機細節(風吹樹葉每一片怎麼晃、光影變化),算力爆表也預測不準,最後只能生成「平均模糊版」或看起來漂亮但物理不通的東西。
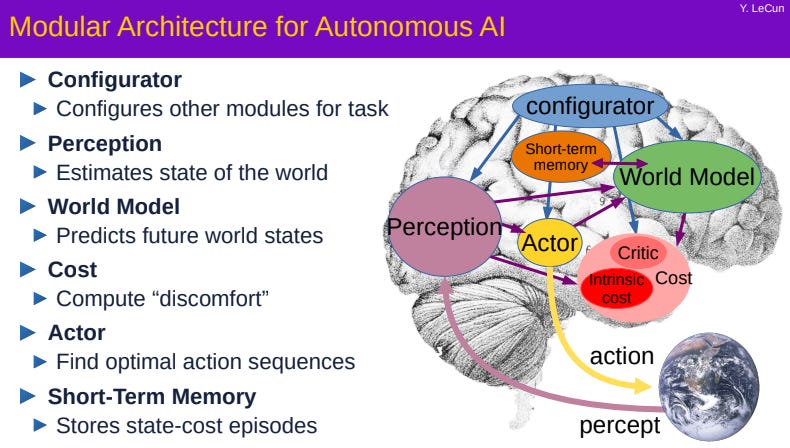
(這張圖就是世界模型的概念:不是像素級生成,而是抽象預測未來狀態)
第二層:真正智能的基石是「預測性世界模型」,不是生成式
楊立昆的核心主張:智能的核心是腦袋裡有一個能預測「我做這件事,世界會怎麼變」的內部模型。
人類/動物不用真的跳崖,就知道會死,因為腦中模擬過後果。這不是靠生成每一個像素畫面,而是在抽象概念空間裡推演。
他推的JEPA(Joint Embedding Predictive Architecture,聯合嵌入預測架構)就是幹這個的:
- 把輸入(影片/圖片)壓成抽象表示(忽略噪音)
- 在抽象空間預測未來狀態
- 只抓穩定的因果關係(例如「樹在風中搖」),不用管每一片葉子
V-JEPA(視覺版JEPA)已經展現初步物理常識:看到球在空中懸停或杯子穿桌子的違物理影片,預測誤差超大,模型會「驚訝」,就像小寶寶看到魔術一樣。

(JEPA基本架構圖:從過去預測未來抽象表示,不是像素重建)

(另一張JEPA如何通往自主智能的腦圖)
第三層:強化學習只是「櫻桃」,不是蛋糕主體
現在ChatGPT好用是因為RLHF(人類反饋強化學習),但楊立昆說這是本末倒置。
他用經典蛋糕比喻:
- 蛋糕本體(90%):自監督學習(看世界、自己總結規律,像嬰兒觀察)
- 糖霜(9%):監督/模仿學習(看專家示範)
- 櫻桃(1%):強化學習(最後微調)
現在業界拼命找櫻桃、想用櫻桃蓋蛋糕,結果AI常一本正經唬爛,因為沒有底層常識。
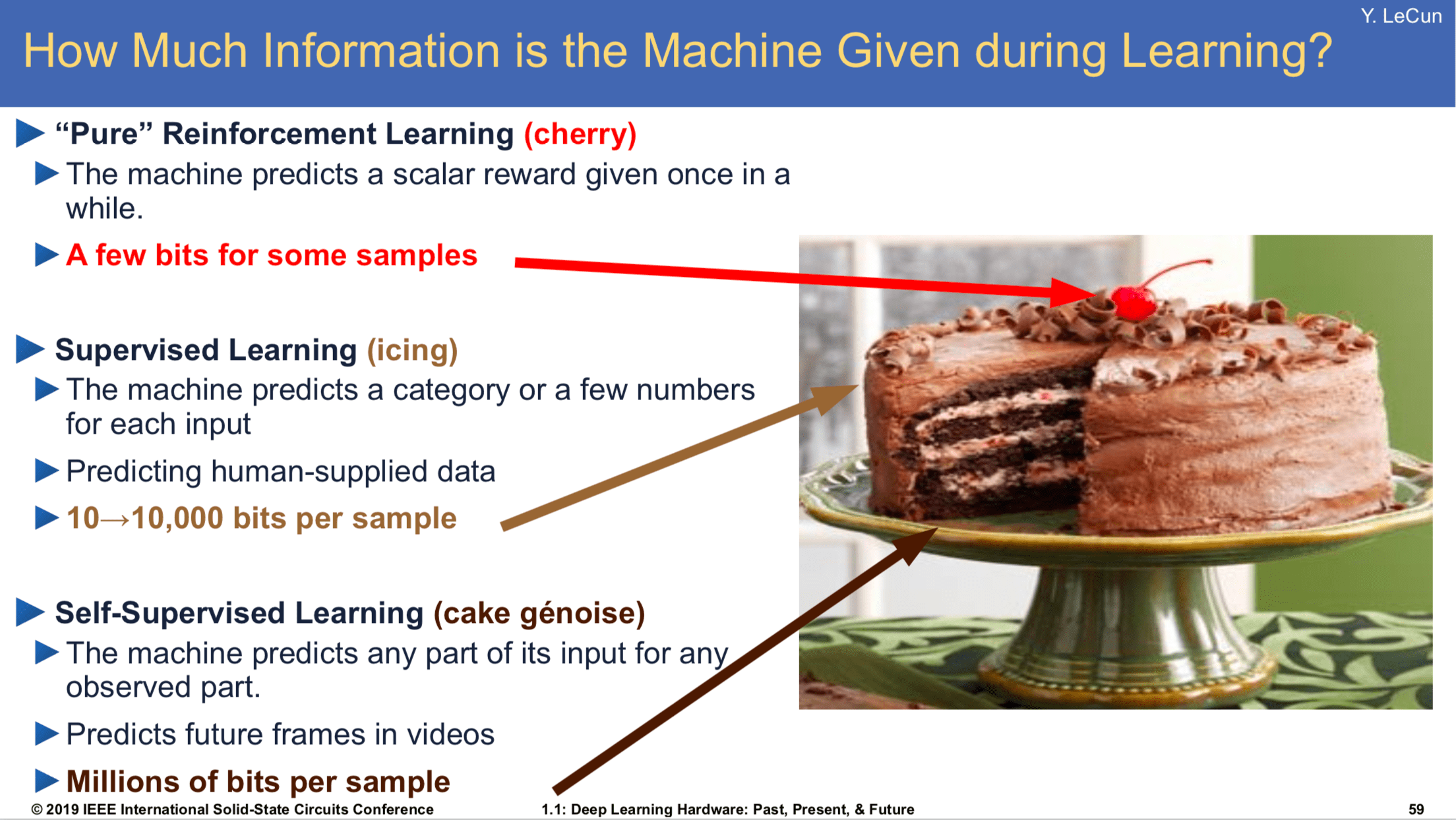
(楊立昆的蛋糕比喻:自監督是主體,RL只是小櫻桃)

(另一版強化學習在蛋糕裡的定位)
第四層:未來靠影片+具身互動,不是更多文字
文本資料再多,也輸給影片資料100倍以上資訊量。影片有物理、光影、碰撞、重力,文本是壓縮後的,缺太多細節。
所以單靠文本永遠到不了人類級智能,必須看世界、摸世界(具身機器人)。
這也解釋他為什麼嗆馬斯克:Optimus雖然在做機器人,但如果腦袋還是生成式/語言模型那一套,路就走歪了。

(馬斯克的Optimus,特斯拉最新人形機器人)

(Optimus站姿,超帥但楊立昆覺得「還不夠聰明」)
第五層:楊立昆的堅持 vs. 現在主流
主流:大力出奇蹟、堆算力、堆文本、生成式通吃一切(OpenAI路線)
楊立昆:反過來,從物理世界預測與規劃下手,學抽象表徵、長程規劃、有理解能力。
他離開Meta就是因為覺得公司太「LLM上頭」,現在自己搞世界模型路線。
總結:這不是兩個大佬吵架,是哲學路線之爭——「語言就是思維」還是「物理世界才是思維基礎」?

(楊立昆本人,圖靈獎得主,現在自己搞AMI Labs,眼神超堅定)

(馬斯克,Optimus的頭號推手,表情永遠在「我就是要幹大事」模式)
楊立昆的五重啟發金句(直接抄他的原話風格)
- 「語言其實很簡單,生成式AI永遠騙不了真正智能」 原味金句:「Language is easy. Generative AI is just pattern matching on compressed symbols. True intelligence comes from understanding the physical world, not just predicting the next token.」 → 啟發:別被ChatGPT寫詩寫code騙了,它只是在玩機率遊戲,沒有真的「懂」世界。未來AI要會「感覺」重力、碰撞、因果,而不是只會背文本。
- 「世界模型才是智能的基石,不是生成像素」 原味金句:「The path to human-level AI is through predictive world models in latent space, not generative reconstruction of every pixel. JEPA learns to predict abstract representations, ignoring irrelevant noise — that's how animals and humans do it.」 → 啟發:人類腦袋不是在腦中重播高清影片,而是抽象預測「如果我這樣做,世界會怎樣變」。JEPA就是在學這個!
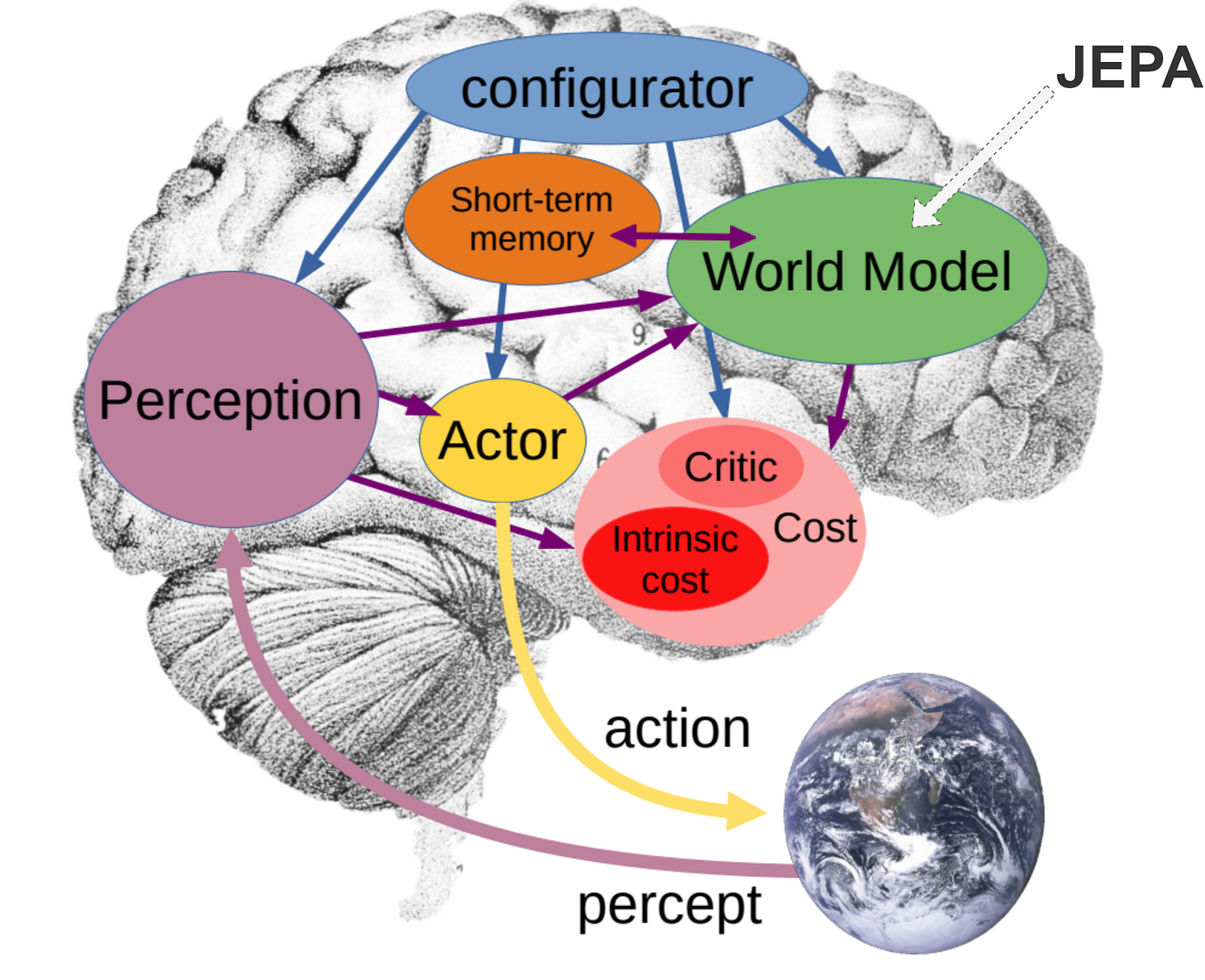
(JEPA世界模型腦圖:從感知到行動,全靠內部預測,不是像素生成)
- 「強化學習只是櫻桃,別用櫻桃蓋蛋糕」 原味金句:「Reinforcement learning is just the cherry on the cake. 90% is self-supervised learning to build world models by observing the world like a baby does — no labels, no rewards needed. The cake is self-supervision, icing is imitation, cherry is RL.」 → 啟發:現在業界瘋狂RLHF、找人類反饋,其實本末倒置。真正的智能基礎是「自己看世界、自己總結規律」,像嬰兒一樣。
(楊立昆經典蛋糕比喻:自監督是厚厚蛋糕本體,RL只是小小一顆櫻桃)
- 「影片資料資訊量比文本高100倍,未來靠物理世界,不是更多文字」 原味金句:「High-quality video contains 100x more information about the physical world than text. Text is highly compressed and abstracted by humans — you'll never reach human-level intelligence by scaling text alone. We need embodied interaction with reality.」 → 啟發:別再卷語料庫了!真正的金礦在YouTube、監控影片、機器人互動裡。Optimus如果腦袋還是語言模型那一套,楊立昆覺得根本走偏。
(Tesla Optimus最新版:看起來帥,但楊立昆說「還缺真正懂世界的腦袋」)
- 「LLM永遠到不了AGI,我知道怎麼做,總有一天你們會發現我對」 原味金句(對馬斯克回擊):「Quite the opposite — I know I can do it, and I know how to do it. The current path everyone is betting on (pure scaling of generative models) is a dead end. World models, planning, and JEPA will win. You'll see.」 → 啟發:這句直接對馬斯克開嗆!楊立昆不是在酸,是真的相信另一條路(非生成式、預測式、世界模型),並且已經在自己公司實幹。3-5年內JEPA可能取代LLM成為主流。
最後總結一句超級啟發金句(楊立昆風格)
「別急著堆算力、堆數據、堆生成,先問自己:這個AI真的懂世界嗎?還是只會模仿人類的壓縮版描述?真正的智能,從理解物理現實開始。」



留言
張貼留言